大数据开源框架之基于Spark的气象数据处理与分析 |
您所在的位置:网站首页 › spark 图像处理 › 大数据开源框架之基于Spark的气象数据处理与分析 |
大数据开源框架之基于Spark的气象数据处理与分析
|
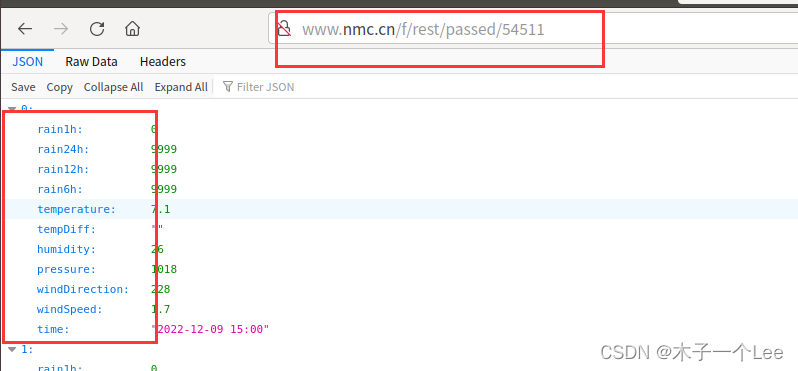
Spark配置请看: (30条消息) 大数据开源框架环境搭建(七)——Spark完全分布式集群的安装部署_木子一个Lee的博客-CSDN博客 目录 实验说明: 实验要求: 实验步骤: 数据获取: 数据分析: 可视化: 参考代码(适用于python3): 运行结果: 实验说明:本次实验所采用的数据,从中央气象台官方网站(网址:http://www.nmc.cn/)爬取,主要是最近24小时各个城市的天气数据,包括时间整点、整点气温、整点降水量、风力、整点气压、相对湿度等。正常情况每个城市对应24条数据(每个整点一条)。数据规模达到2412个城市,57888条数据,有部分城市部分时间点数据存在缺失或异常。特别说明:实验所用数据均为网上爬取,没有得到中央气象台官方授权使用,使用范围仅限本次实验使用,请勿用于商业用途。 实验要求:1.数据获取,最后保存的各个城市最近24小时整点天气数据(passed_weather_ALL.csv)每条数据各字段含义如下所示,这里仅列出实验中使用部分: 字段 含义 字段 含义 province 城市所在省份(中文) province 城市所在省份(中文) city_index 城市序号(计数) city_index 城市序号(计数) city_name 城市名称(中文) city_name 城市名称(中文) city_code 城市编号 city_code 城市编号 time 时间点(整点) time 时间点(整点) temperature 气温 temperature 气温 rain1h 过去1小时降雨量; rain1h 过去1小时降雨量; 2. 数据分析,主要使用Spark SQL相关知识与技术,对各个城市过去24小时累积降雨量和当日平均气温进行计算和排序; 3. 数据可视化,数据可视化使用python matplotlib库,版本号1.5.1。可使用pip命令安装。绘制过程大体如下: 第一步,应当设置字体,这里提供了黑体的字体文件simhei.tff。否则坐标轴等出现中文的地方是乱码。 第二步,设置数据(累积雨量或者日平均气温)和横轴坐标(城市名称),配置直方图。 第三步,配置横轴坐标位置,设置纵轴坐标范围 第四步,配置横纵坐标标签 第五步,配置每个条形图上方显示的数据 第六步,根据上述配置,画出直方图。。 根据上述实验任务,设计相应内容与具体执行步骤,并对相应关键步骤的执行结果给出截图。 实验步骤: 数据获取:思路: 首先利用urllib.request获取url的数据,然后利用json.loads变为json格式
再编写函数写入表头和数据:
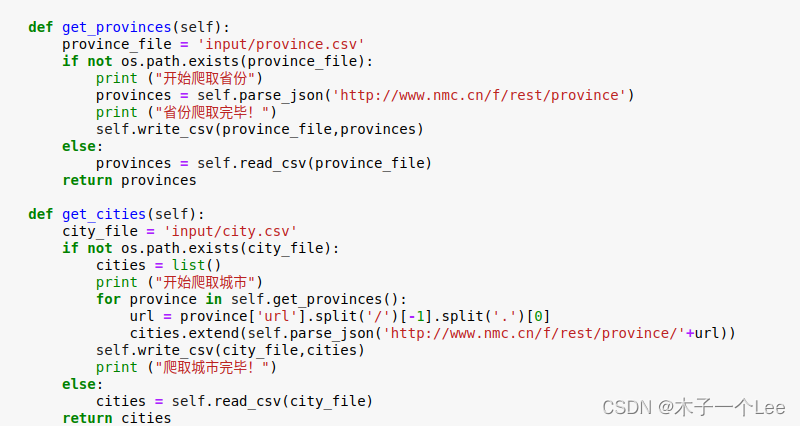
利用上述函数组合,编写两个get函数获取城市和省份,导出CSV文件:
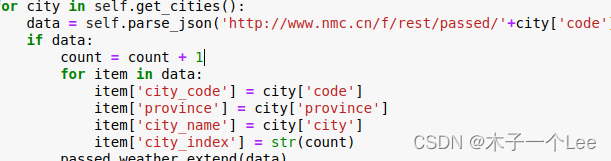
最后获取天气数据,导出passed_weather_ALL.csv 每个字段获取方式是: city_code就是city.csv的code,province就是city.csv里边的province,city_name就是city.csv里边的city,city_index就是第几个城市(设置count变量计数,每个城市加1),
其他直接通过爬取表头获得:
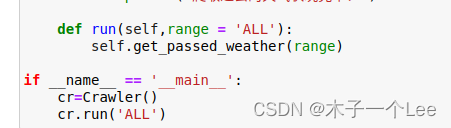
在主函数里运行:
部分代码: def get_passed_weather(self,province): weather_passed_file = 'input/passed_weather_' + province + '.csv' if os.path.exists(weather_passed_file): return passed_weather = list() count = 0 if province == 'ALL': print ("开始爬取过去的天气状况") for city in self.get_cities(): data = self.parse_json('http://www.nmc.cn/f/rest/passed/'+city['code']) if data: count = count + 1 for item in data: item['city_code'] = city['code'] item['province'] = city['province'] item['city_name'] = city['city'] item['city_index'] = str(count) passed_weather.extend(data) if count % 50 == 0: if count == 50: self.write_header(weather_passed_file,passed_weather) else: self.write_row(weather_passed_file,passed_weather) passed_weather = list() if passed_weather: if count |


【本文地址】